Web Scraping on dynamic website(CSR) with python and selenium

Introduction
There are many ways for web scraping nowadays whether with Javascript(which I think is the easiest one) or other programming languages. In this article, I will focus on Python because you know this is the age of Data Science and Data scientist love Python also I’m recently obsessed with Data analyst field.
There are 3 popular libraries to work on Web scraping with Python which are Selenium, Beautiful Soup, and Scrapy (How they’re different you can watch this youtube video). This content I will show you how to work with Selenium and Beautiful Soup which is intuitive and easy to implement.
Prerequisites
- Install selenium and Beautiful Soup packages
pip install seleniumpip install BeautifulSoup4
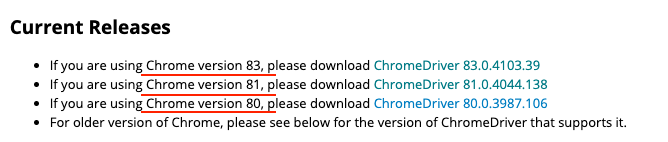
Let's Start
I will scrape the whole reverb guitar search page source as an example.
from bs4 import BeautifulSoupfrom selenium import webdriverimport timedriver = webdriver.Chrome('directory/to/web_driver')driver.get("https://reverb.com/marketplace/electric-guitars?make=fender&page=1")time.sleep(3)html_source = driver.page_sourcesoup = BeautifulSoup(html_source,'lxml')
As you can see only 5 lines of code, We have a whole HTML page source from a specific URL. I will explain line by line from the above chunk of code.
1.Execute web driver (The one downloaded) and store to driver variable
driver = webdriver.Chrome('directory/to/web_driver')2. Tell web driver to open URL
driver.get("https://reverb.com/marketplace/electric-guitars?make=fender&page=1")3. This line is very important we need to set the sleep time and wait for the web page to fully loaded because It’s a Dynamic website or some call Client Side Rendered(CSR). You can read more about CSR and other types here.
time.sleep(3)4. Get page source
html_source = driver.page_source5. Call Beautiful Soup and parse HTML source in any parse you want. You can finf parser options from Beautiful Soup documents here.
soup = BeautifulSoup(html_source,'lxml')So yeah, That’s pretty much it. How to web scraping in a very simple way.
Bonus
What if you want to know all the guitar products name and prices. Basically, After we scraped page source which means we have every information on that specific page. We can use Beautiful Soup to get those particular informations.
The concept is very easy. Search for tag, class, or id that store product name or whatever you want to know. (we will use those tag, class, or id as an arguments for Beautiful Soup). You can used inspect element feature in google chrome to find out what tag, class, or id by press cmd+opt+i in mac.
Product name
For product name after I inspected the HTML source, I found that product name is in ‘h4’ tag and class ‘grid-card__title’
I’ve already stored HTML source in soup variable so I can call a function call ‘find_all’ and pass 2 arguments the first one is tag name and class name to find a product name.
all_product_name = soup.find_all('h4', class_='grid-card__title')Here’s the result below, You can see that we have all specific h4 tag and class grid-card__title.

So what if we want only the text inside those tag ?? just use .text function and loop through this list.
[i.text for i in all_product_name]BAM! We got what we want.

Conclusion
Scraping page source
- Install Selenium
- Install Beautiful Soup
- Download web driver
- Get specific information after scraped with Beautiful Soup
And that’s all a basic of web scraping on dynamic website in just 5 lines of code. :)
Github : Source code
Github Gist : Source code